

Tembo were invited to do a short presentation of the pg_timeseries extension to the Chicago Postgres User Group in August. As expected, user questions popped up which didn’t have an immediate obvious answer, mainly related to performance. Is Hydra Columnar storage used by pg_timeseries faster than Heap when it comes to inserts? How about updates or deletes? Does the overall row count affect these results?
So why not run some tests?
Benchmark Procedure
Any proper benchmark needs a testing procedure. We performed a few simple test runs which showed interesting results, but these initial findings were soon erased once the more objective and standardized process emerged.
All code used for these tests is available in this GitHub directory rather than inline with the blog. Including it here would be somewhat distracting, as it’s a lot of code. But we can explore the function names, if only for amusement sake.
The process works like this:
- Create the
divvy_tripspartition tables. - Create the
sample_datatable to hold test results. - Create the
chungustable to contain generated test data. - Execute
sp_run_teststo run all of the tests, which will:- Call
sp_set_storageto start with heap storage. - For the requested test count and chunk size:
- Call
sp_scale_chungusto generate data for that test iteration chunk size. - Truncate the
divvy_tripstable. - Call
sp_insert_testfor insert timings. - Call
sp_update_testfor update timings. - Call
sp_delete_testfor delete timings. - Repeat all insert, update, delete tests 5 times for accuracy.
- Call
- Repeat the entire test process for columnar storage.
- Call
- Wait.
- Check the
sample_datatable for results.
Yes, the data staging table is named chungus; depending on the requested chunk size, it can be pretty hefty. Truth in advertising is important after all!
The test itself utilizes only three physical tables: divvy_trips to store simulated Divvy data, chungus as a staging area for pre-generated content, and sample_data to store test results. This allows us to generate thousands or millions of rows for the various phases of our tests, without tainting the results with calculation times.
If you want to read more about the process we used, we discuss the entire procedure in the linked GitHub project.
Running the Benchmark
The benchmark is entirely controlled by the sp_run_tests function that requires the number of tests, and the amount of cumulative rows per test. That means we can run our tests using however many chunks and iterations as we desire. For example:
CALL sp_run_tests(20, 250000);This would run 20 tests starting at 250,000 rows and ending at five million rows (250,000 * 20). This lets us see if row count affects timings and to what extent. The results are categorized by row count, storage type, and write action, so we can slice and dice it several different ways as well.
Performance Explored
The data we collected used the same parameters as in the above example: 20 samples at 250,000 rows per step, for a total maximum of 5 million rows on the last iteration. We split the results into inserts, updates, and deletes for both Heap and Columnar storage types and graphed the results.
Let’s start with inserts:
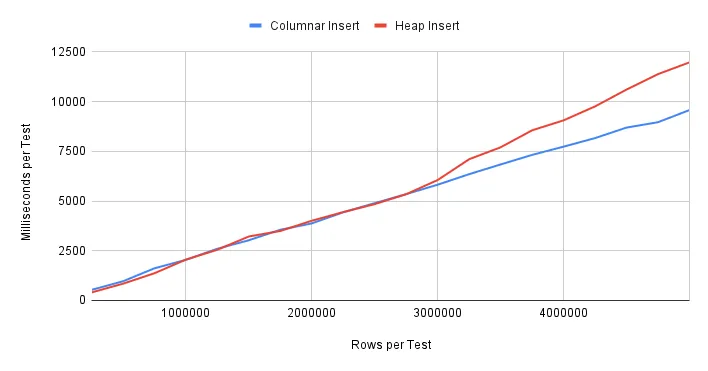
We can see from these results that the heap and columnar results are practically identical until about 3M rows. We would almost expect this from the built-in column compression. As row density increases, new column data has more chances to integrate into an existing compression histogram.
Update performance is a bit different:
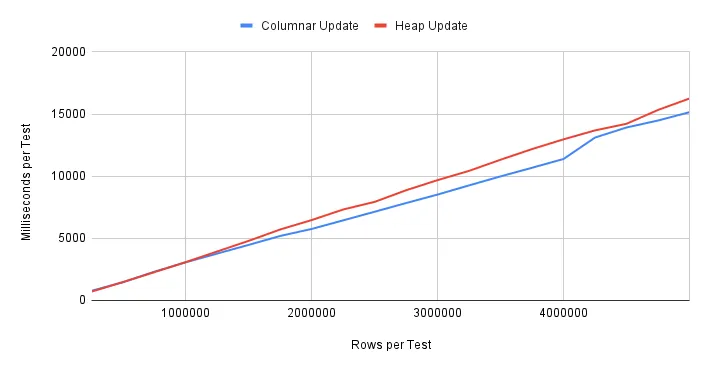
Columnar performance is still better, but not by much. Consider the implications here. Insert performance is clearly superior, but what about updates? Columnar data isn’t generally designed to accommodate updates, so we observe a smaller margin of improvement over standard heap storage. Regardless, it’s still slightly faster.
Delete performance on the other hand, is a significant departure from either inserts or updates:
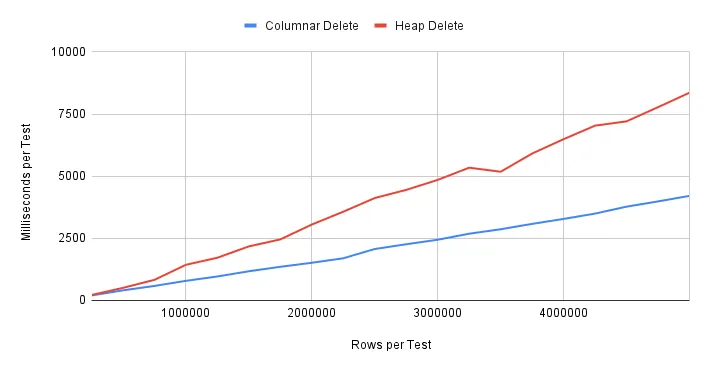
In this case, deletes are immediately faster, and the gap simply widens as volume increases. We don’t know what algorithm is at work here with the columnar storage, but there’s clearly a benefit compared to heap.
Final Words
Keep in mind that these tests are specific to Hydra columnar storage. It’s entirely possible that other columnar storage engines will perform differently using this test suite. With this in mind, it’s interesting to see that the results are very close in most regards given the vastly different underlying storage techniques.
We were expecting write overhead to suffer given the inherent compression, but it appears the benefits slightly outweigh the costs for this particular data. Regardless, these measurements seem to indicate that there’s no performance risk to using pg_timeseries for managing columnar data. In fact, the end result will likely be slightly faster than using pure Postgres heap partitions.
That’s not quite what we were expecting, but it’s a welcome surprise. We’d love to expand the test routines to cover more usage patterns and try it against other Postgres storage engines and compare the results. Are there any others you would recommend? Let us know your thoughts on X at @tembo_io or Join the Tembo Slack community and let us know!